Node类型
每个节点都有一个 nodeType 属性,用于表明节点的类型。节点类型由在 Node 类型中定义的下列12 个数值常量来表示,任何节点类型必居其一:
- Node.ELEMENT_NODE (1)
- Node.ATTRIBUTE_NODE (2)
- Node.TEXT_NODE (3)
- Node.CDATA_SECTION_NODE (4)
- Node.ENTITY_REFERENCE_NODE (5)
- Node.ENTITY_NODE (6)
- Node.PROCESSING_INSTRUCTION_NODE (7)
- Node.COMMENT_NODE (8)
- Node.DOCUMENT_NODE (9)
- Node.DOCUMENT_TYPE_NODE (10)
- Node.DOCUMENT_FRAGMENT_NODE (11)
- Node.NOTATION_NODE (12)
通过比较上面这些常量,可以很容易地确定节点的类型,例如:
if (someNode.nodeType == 1) {
// 适用于所有浏览器
alert("Node is an element.");
}1. nodeName 和 nodeValue 属性
要了解节点的具体信息,可以使用 nodeName 和 nodeValue 这两个属性。
if (someNode.nodeType == 1) {
value = someNode.nodeName; //nodeName 的值是元素的标签名
}在这个例子中,首先检查节点类型,看它是不是一个元素。如果是,则取得并保存 nodeName 的值。对于元素节点, nodeName 中保存的始终都是元素的标签名,而 nodeValue 的值则始终为 null 。
2. 节点关系
每个节点都有一个 childNodes 属性,其中保存着一个 NodeList 对象。 NodeList 是一种类数组对象,用于保存一组有序的节点,可以通过位置来访问这些节点。
NodeList 对象的独特之处在于,它实际上是基于 DOM 结构动态执行查询的结果,因此 DOM 结构的变化能够自动反映在 NodeList 对象中。
下面的例子展示了如何访问保存在 NodeList 中的节点——可以通过方括号,也可以使用 item()方法。
var firstChild = someNode.childNodes[0];
var secondChild = someNode.childNodes.item(1);
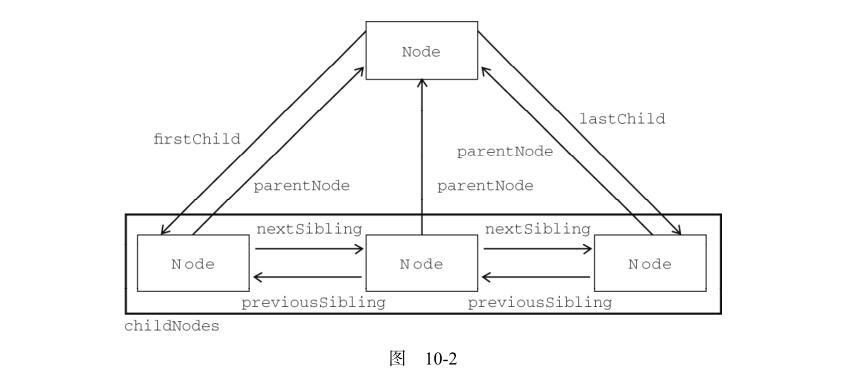
var count = someNode.childNodes.length;每个节点都有一个 parentNode 属性,该属性指向文档树中的父节点。包含在 childNodes 列表中的所有节点都具有相同的父节点,因此它们的 parentNode 属性都指向同一个节点。
包含在childNodes 列表中的每个节点相互之间都是同胞节点。通过使用列表中每个节点的 previousSibling和 nextSibling 属性,可以访问同一列表中的其他节点。列表中第一个节点的 previousSibling 属性值为 null ,而列表中最后一个节点的 nextSibling 属性的值同样也为 null。
父节点与其第一个和最后一个子节点之间也存在特殊关系。父节点的 firstChild 和 lastChild属性分别指向其 childNodes 列表中的第一个和最后一个节点。如果没有子节点,那么 firstChild 和 lastChild 的值均为 null 。
图 10-2 形象地展示了上述关系。
另外, hasChildNodes() 也是一个非常有用的方法,这个方法在节点包含一或多个子节点的情况下返回 true ;应该说,这是比查询 childNodes列表的 length 属性更简单的方法。
所有节点都有的最后一个属性是 ownerDocument ,该属性指向表示整个文档的文档节点。
3. 操作节点
最常用的方法是appendChild() ,用于向 childNodes 列表的末尾添加一个节点,返回新增的节点。
如果传入到 appendChild() 中的节点已经是文档的一部分了,那结果就是将该节点从原来的位置转移到新位置。任何 DOM 节点不能同时出现在文档中的多个位置上。
如下面的例子所示。
//someNode 有多个子节点
var returnedNode = someNode.appendChild(someNode.firstChild);
alert(returnedNode == someNode.firstChild); //false
alert(returnedNode == someNode.lastChild); //true如果需要把节点放在 childNodes 列表中某个特定的位置上,而不是放在末尾,那么可以使用insertBefore() 方法。
这个方法接受两个参数:要插入的节点和作为参照的节点。插入节点后,被插 入的节点会变成参照节点的前一个同胞节点( previousSibling ),同时被方法返回。如果参照节点是null ,则 insertBefore() 与 appendChild() 执行相同的操作。
replaceChild() 方法接受的两个参数是:要插入的节点和要替换的节点。要替换的节点将由这个方法返回并从文档树中被移除,同时由要插入的节点占据其位置。
在使用 replaceChild() 插入一个节点时,该节点的所有关系指针都会从被它替换的节点复制过来。尽管从技术上讲,被替换的节点仍然还在文档中,但它在文档中已经没有了自己的位置。
如果只想移除而非替换节点,可以使用 removeChild() 方法。这个方法接受一个参数,即要移除的节点。被移除的节点将成为方法的返回值。
4. 其他方法
有两个方法是所有类型的节点都有的。第一个就是 cloneNode() ,用于创建调用这个方法的节点的一个完全相同的副本。
cloneNode() 方法接受一个布尔值参数,表示是否执行深复制。在参数为 true的情况下,执行深复制,也就是复制节点及其整个子节点树;在参数为 false 的情况下,执行浅复制,即只复制节点本身。
cloneNode() 方法不会复制添加到 DOM 节点中的 JavaScript 属性,例如事件处理程序等。这个方法只复制特性、(在明确指定的情况下也复制)子节点,其他一切都不会复制。IE 在此存在一个 bug,即它会复制事件处理程序,所以我们建议在复制之前最好先移除事件处理程序。
我们要介绍的最后一个方法是 normalize() ,这个方法将当前节点和它的后代节点”规范化“(normalized)。在一个"规范化"后的DOM树中,不存在一个空的文本节点,或者两个相邻的文本节点。